1.SpringAMQP
将来我们开发业务功能的时候,肯定不会在控制台收发消息,而是应该基于编程的方式。由于RabbitMQ采用了AMQP协议,因此它具备跨语言的特性。任何语言只要遵循AMQP协议收发消息,都可以与RabbitMQ交互。并且RabbitMQ官方也提供了各种不同语言的客户端。
但是,RabbitMQ官方提供的Java客户端编码相对复杂,一般生产环境下我们更多会结合Spring来使用。而Spring的官方刚好基于RabbitMQ提供了这样一套消息收发的模板工具:SpringAMQP。并且还基于SpringBoot对其实现了自动装配,使用起来非常方便。
SpringAmqp的官方地址:
Spring AMQP
SpringAMQP提供了三个功能:
自动声明队列、交换机及其绑定关系
基于注解的监听器模式,异步接收消息
封装了RabbitTemplate工具,用于发送消息
这一章我们就一起学习一下,如何利用SpringAMQP实现对RabbitMQ的消息收发。
1.1.导入Demo工程
在课前资料给大家提供了一个Demo工程,方便我们学习SpringAMQP的使用:
将其复制到你的工作空间,然后用Idea打开,项目结构如图:
包括三部分:
- mq-demo:父工程,管理项目依赖
- publisher:消息的发送者
- consumer:消息的消费者
在mq-demo这个父工程中,已经配置好了SpringAMQP相关的依赖:
1 |
|
因此,子工程中就可以直接使用SpringAMQP了。
1.2.快速入门
在之前的案例中,我们都是经过交换机发送消息到队列,不过有时候为了测试方便,我们也可以直接向队列发送消息,跳过交换机。
在入门案例中,我们就演示这样的简单模型,如图:
也就是:
- publisher直接发送消息到队列
- 消费者监听并处理队列中的消息
:::warning
注意:这种模式一般测试使用,很少在生产中使用。
:::
为了方便测试,我们现在控制台新建一个队列:simple.queue
添加成功:
接下来,我们就可以利用Java代码收发消息了。
1.2.1.消息发送
首先配置MQ地址,在publisher服务的application.yml中添加配置:
1 | spring: |
然后在publisher服务中编写测试类SpringAmqpTest,并利用RabbitTemplate实现消息发送:
1 | package com.itheima.publisher.amqp; |
打开控制台,可以看到消息已经发送到队列中:
接下来,我们再来实现消息接收。
1.2.2.消息接收
首先配置MQ地址,在consumer服务的application.yml中添加配置:
1 | spring: |
然后在consumer服务的com.itheima.consumer.listener包中新建一个类SpringRabbitListener,代码如下:
1 | package com.itheima.consumer.listener; |
1.2.3.测试
启动consumer服务,然后在publisher服务中运行测试代码,发送MQ消息。最终consumer收到消息:
1.3.WorkQueues模型
Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息。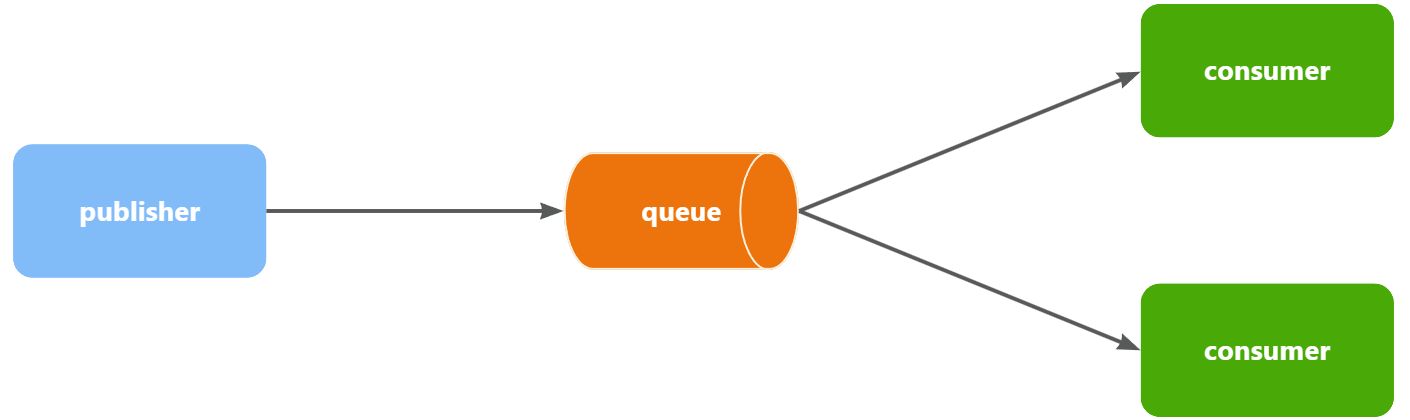
当消息处理比较耗时的时候,可能生产消息的速度会远远大于消息的消费速度。长此以往,消息就会堆积越来越多,无法及时处理。
此时就可以使用work 模型,多个消费者共同处理消息处理,消息处理的速度就能大大提高了。
接下来,我们就来模拟这样的场景。
首先,我们在控制台创建一个新的队列,命名为work.queue:
1.3.1.消息发送
这次我们循环发送,模拟大量消息堆积现象。
在publisher服务中的SpringAmqpTest类中添加一个测试方法:
1 | /** |
1.3.2.消息接收
要模拟多个消费者绑定同一个队列,我们在consumer服务的SpringRabbitListener中添加2个新的方法:
1 |
|
注意到这两消费者,都设置了Thead.sleep,模拟任务耗时:
- 消费者1 sleep了20毫秒,相当于每秒钟处理50个消息
- 消费者2 sleep了200毫秒,相当于每秒处理5个消息
1.3.3.测试
启动ConsumerApplication后,在执行publisher服务中刚刚编写的发送测试方法testWorkQueue。
最终结果如下:
1 | 消费者1接收到消息:【hello, message_0】21:06:00.869555300 |
可以看到消费者1和消费者2竟然每人消费了25条消息:
- 消费者1很快完成了自己的25条消息
- 消费者2却在缓慢的处理自己的25条消息。
也就是说消息是平均分配给每个消费者,并没有考虑到消费者的处理能力。导致1个消费者空闲,另一个消费者忙的不可开交。没有充分利用每一个消费者的能力,最终消息处理的耗时远远超过了1秒。这样显然是有问题的。
1.3.4.能者多劳
在spring中有一个简单的配置,可以解决这个问题。我们修改consumer服务的application.yml文件,添加配置:
1 | spring: |
再次测试,发现结果如下:
1 | 消费者1接收到消息:【hello, message_0】21:12:51.659664200 |
可以发现,由于消费者1处理速度较快,所以处理了更多的消息;消费者2处理速度较慢,只处理了6条消息。而最终总的执行耗时也在1秒左右,大大提升。
正所谓能者多劳,这样充分利用了每一个消费者的处理能力,可以有效避免消息积压问题。
1.3.5.总结
Work模型的使用:
- 多个消费者绑定到一个队列,同一条消息只会被一个消费者处理
- 通过设置prefetch来控制消费者预取的消息数量