RAG (检索增强生成)
LLM 的知识仅限于它已经训练过的数据。 如果你想让 LLM 了解特定领域的知识或专有数据,你可以:
- 使用 RAG,我们将在本节中介绍
- 用你的数据微调 LLM
- 结合 RAG 和微调
什么是 RAG?
简单来说,RAG 是一种在发送给 LLM 之前,从你的数据中找到并注入相关信息片段到提示中的方法。 这样 LLM 将获得(希望是)相关信息,并能够使用这些信息回复, 这应该会降低产生幻觉的概率。
相关信息片段可以使用各种信息检索方法找到。 最流行的方法有:
- 全文(关键词)搜索。这种方法使用 TF-IDF 和 BM25 等技术, 通过匹配查询(例如,用户提问的内容)中的关键词与文档数据库进行搜索。 它根据每个文档中这些关键词的频率和相关性对结果进行排名。
- 向量搜索,也称为”语义搜索”。 文本文档使用嵌入模型转换为数字向量。 然后根据查询向量和文档向量之间的余弦相似度 或其他相似度/距离度量找到并排序文档, 从而捕捉更深层次的语义含义。
- 混合搜索。结合多种搜索方法(例如,全文 + 向量)通常可以提高搜索的有效性。
目前,本页主要关注向量搜索。 全文和混合搜索目前仅由 Azure AI Search 集成支持, 详情请参阅 AzureAiSearchContentRetriever。 我们计划在不久的将来扩展 RAG 工具箱,包括全文和混合搜索。
RAG 的执行流程如下:
1 | 用户问题 |
RAG 阶段
RAG 过程分为两个不同的阶段:索引和检索。 LangChain4j 为这两个阶段提供了工具。
索引
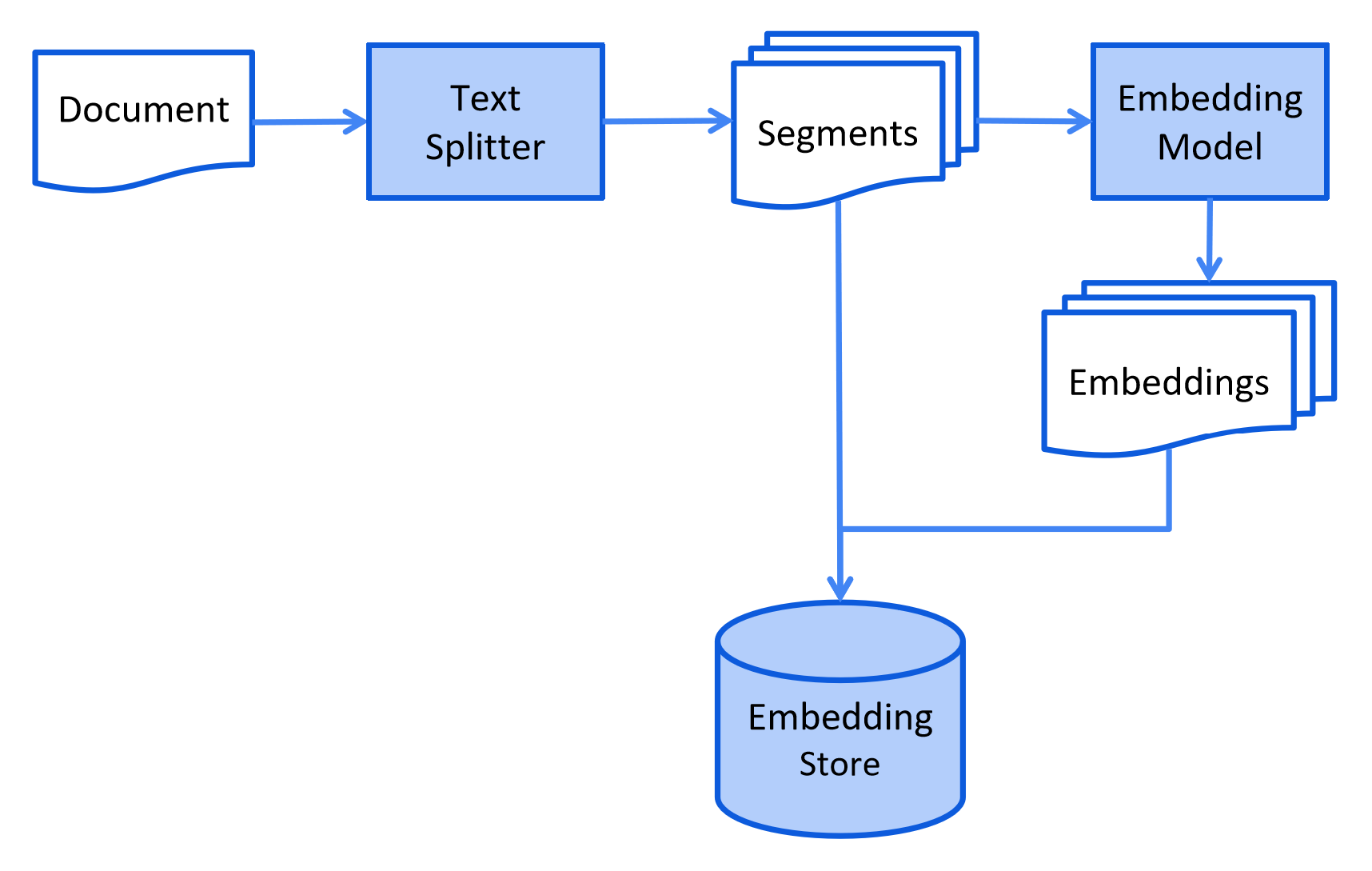
在索引阶段,文档会被预处理,以便在检索阶段进行高效搜索。
这个过程可能因使用的信息检索方法而异。 对于向量搜索,这通常涉及清理文档、用额外数据和元数据丰富文档、 将文档分割成更小的片段(也称为分块)、嵌入这些片段,最后将它们存储在嵌入存储(也称为向量数据库)中。
索引阶段通常是离线进行的,这意味着最终用户不需要等待其完成。 例如,可以通过定时任务在周末每周重新索引一次公司内部文档来实现。 负责索引的代码也可以是一个单独的应用程序,只处理索引任务。
然而,在某些情况下,最终用户可能希望上传自己的自定义文档,使 LLM 能够访问这些文档。 在这种情况下,索引应该在线进行,并成为主应用程序的一部分。
以下是索引阶段的简化图表:
检索
检索阶段通常在线进行,当用户提交一个应该使用索引文档回答的问题时。
这个过程可能因使用的信息检索方法而异。 对于向量搜索,这通常涉及嵌入用户的查询(问题) 并在嵌入存储中执行相似度搜索。 然后将相关片段(原始文档的片段)注入到提示中并发送给 LLM。
以下是检索阶段的简化图表: 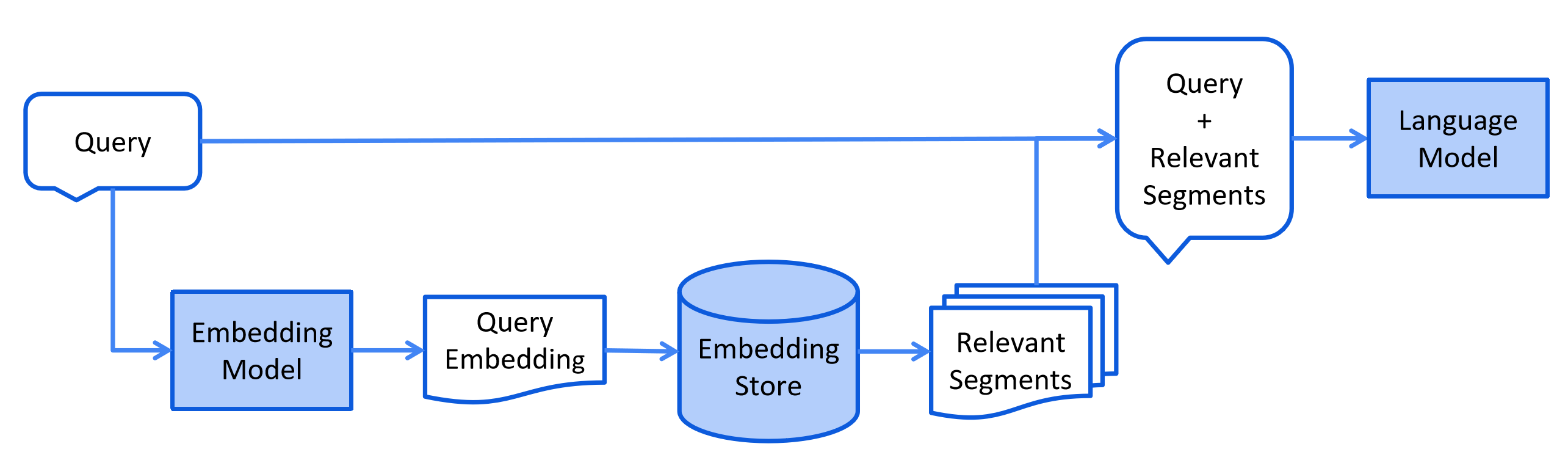
LangChain4j 中的 RAG 风格
LangChain4j 提供了三种 RAG 风格:
- Easy RAG:开始使用 RAG 的最简单方式
- Naive RAG:使用向量搜索的基本 RAG 实现
- Advanced RAG:一个模块化的 RAG 框架,允许额外的步骤,如 查询转换、从多个来源检索和重新排序
Easy RAG
LangChain4j 有一个”Easy RAG”功能,使开始使用 RAG 变得尽可能简单。 你不必了解嵌入、选择向量存储、找到合适的嵌入模型、 弄清楚如何解析和分割文档等。 只需指向你的文档,LangChain4j 将完成其魔法。
备注
当然,这种”Easy RAG”的质量会低于定制的 RAG 设置。 然而,这是开始学习 RAG 和/或制作概念验证的最简单方法。 之后,你将能够平稳地从 Easy RAG 过渡到更高级的 RAG, 调整和定制更多方面。
- 导入
langchain4j-easy-rag依赖:
1 | <dependency> |
- 让我们加载你的文档:
1 | List<Document> documents = FileSystemDocumentLoader.loadDocuments("/home/langchain4j/documentation"); |
这将加载指定目录中的所有文件。
底层使用 Apache Tika 库,它支持各种文档类型, 用于检测文档类型并解析它们。 由于我们没有明确指定使用哪个
DocumentParser,FileSystemDocumentLoader将通过 SPI 加载ApacheTikaDocumentParser, 由langchain4j-easy-rag依赖提供。
- 现在,我们需要预处理文档并将其存储在专门的嵌入存储(也称为向量数据库)中。 这对于在用户提问时快速找到相关信息片段是必要的。 我们可以使用我们支持的 15+ 嵌入存储中的任何一个, 但为了简单起见,我们将使用内存中的存储:
1 | InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>(); |
EmbeddingStoreIngestor通过 SPI 从langchain4j-easy-rag依赖加载DocumentSplitter。 每个Document被分割成更小的片段(TextSegment),每个片段不超过 300 个令牌, 并有 30 个令牌的重叠。EmbeddingStoreIngestor通过 SPI 从langchain4j-easy-rag依赖加载EmbeddingModel。 每个TextSegment使用EmbeddingModel转换为Embedding。
案例:实现Easy RAG
1 | //聊天模型 |
- 准备文档
1 | 咏鸡 |
- 文档解析入库
- 用户提问


Document
Document 类表示整个文档,如单个 PDF 文件或网页。 目前,Document 只能表示文本信息, 但未来的更新将使其支持图像和表格。
Document.text()返回Document的文本Document.metadata()返回Document的Metadata(参见下面的”Metadata”部分)Document.toTextSegment()将Document转换为TextSegment(参见下面的”TextSegment”部分)Document.from(String, Metadata)从文本和Metadata创建DocumentDocument.from(String)从文本创建带有空Metadata的Document
Metadata
每个 Document 包含 Metadata。 它存储关于 Document 的元信息,如其名称、来源、最后更新日期、所有者, 或任何其他相关细节。
Metadata 存储为键值映射,其中键为 String 类型, 值可以是以下类型之一:String、Integer、Long、Float、Double。
Metadata 有几个用途:
- 在将
Document的内容包含在提示中时, 元数据条目也可以包括在内,为 LLM 提供额外的信息考虑。 例如,提供Document名称和来源可以帮助提高 LLM 对内容的理解。 - 在搜索相关内容以包含在提示中时, 可以通过
Metadata条目进行过滤。 例如,你可以将语义搜索范围缩小到仅属于特定所有者的Document。 - 当
Document的来源更新时(例如,文档的特定页面), 可以通过其元数据条目(例如,”id”、”source”等)轻松定位相应的Document, 并在EmbeddingStore中更新它以保持同步。
Metadata.from(Map)从Map创建MetadataMetadata.put(String key, String value)/put(String, int)/ 等,向Metadata添加条目Metadata.putAll(Map)向Metadata添加多个条目Metadata.getString(String key)/getInteger(String key)/ 等,返回Metadata条目的值,将其转换为所需类型Metadata.containsKey(String key)检查Metadata是否包含指定键的条目Metadata.remove(String key)通过键从Metadata中删除条目
TextSegment.text()返回TextSegment的文本TextSegment.metadata()返回TextSegment的MetadataTextSegment.from(String, Metadata)从文本和Metadata创建TextSegmentTextSegment.from(String)从文本创建带有空Metadata的TextSegment
Document Splitter
LangChain4j 有一个 DocumentSplitter 接口,带有几个开箱即用的实现:
DocumentByParagraphSplitterDocumentByLineSplitterDocumentBySentenceSplitterDocumentByWordSplitterDocumentByCharacterSplitterDocumentByRegexSplitter- 递归:
DocumentSplitters.recursive(...)
它们的工作方式如下:
- 你实例化一个
DocumentSplitter,指定所需的TextSegment大小, 并可选择指定字符或令牌的重叠。 - 你调用
DocumentSplitter的split(Document)或splitAll(List<Document>)方法。 DocumentSplitter将给定的Document分割成更小的单元, 这些单元的性质因分割器而异。例如,DocumentByParagraphSplitter将 文档分成段落(由两个或更多连续的换行符定义), 而DocumentBySentenceSplitter使用 OpenNLP 库的句子检测器将 文档分成句子,等等。- 然后,
DocumentSplitter将这些更小的单元(段落、句子、单词等)组合成TextSegment, 尝试在不超过步骤 1 中设置的限制的情况下,在单个TextSegment中包含尽可能多的单元。 如果某些单元仍然太大而无法放入TextSegment,它会调用子分割器。 这是另一个DocumentSplitter,能够将不适合的单元分割成更细粒度的单元。 所有Metadata条目都从Document复制到每个TextSegment。 每个文本片段都添加了一个唯一的元数据条目”index”。 第一个TextSegment将包含index=0,第二个index=1,依此类推。
Text Segment Transformer
TextSegmentTransformer 类似于 DocumentTransformer(上面描述的),但它转换 TextSegment。
与 DocumentTransformer 一样,没有一种通用的解决方案, 所以我们建议实现你自己的 TextSegmentTransformer,根据你独特的数据定制。
一种对改善检索效果很好的技术是在每个 TextSegment 中包含 Document 标题或简短摘要。
Embedding
Embedding 类封装了一个数值向量,表示已嵌入内容(通常是文本,如 TextSegment)的”语义含义”。
Embedding.dimension()返回嵌入向量的维度(其长度)CosineSimilarity.between(Embedding, Embedding)计算两个Embedding之间的余弦相似度Embedding.normalize()规范化嵌入向量(就地)
Embedding Model
EmbeddingModel 接口表示一种特殊类型的模型,将文本转换为 Embedding。
当前支持的嵌入模型可以在这里找到。
EmbeddingModel.embed(String)嵌入给定的文本EmbeddingModel.embed(TextSegment)嵌入给定的TextSegmentEmbeddingModel.embedAll(List<TextSegment>)嵌入所有给定的TextSegmentEmbeddingModel.dimension()返回此模型产生的Embedding的维度
案例: 生产级RAG落地
1 | /** |