朴素贝叶斯与聚类
朴素贝叶斯
朴素贝叶斯介绍
- 复习常见概率的计算
- 知道贝叶斯公式
- 了解朴素贝叶斯是什么
- 了解拉普拉斯平滑系数的作用
【知道】常见的概率公式
条件概率: 表示事件A在另外一个事件B已经发生条件下的发生概率,P(A|B)
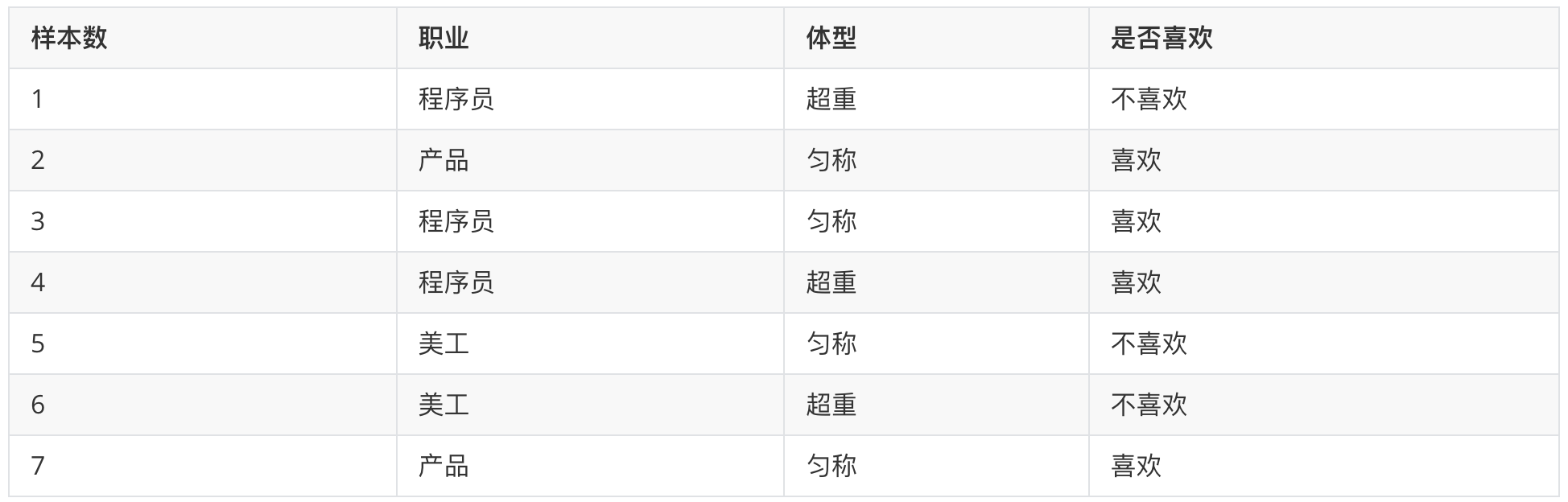
在女神喜欢的条件下,职业是程序员的概率?
- 女神喜欢条件下,有 2、3、4、7 共 4 个样本
- 4 个样本中,有程序员 3、4 共 2 个样本
- 则 P(程序员|喜欢) = 2/4 = 0.5
联合概率: 表示多个条件同时成立的概率,P(AB) = P(A) P(B|A)
特征条件独立性假设:P(AB) = P(A) P(B)
职业是程序员并且体型匀称的概率?
- 数据集中,共有 7 个样本
- 职业是程序员有 1、3、4 共 3 个样本,则其概率为:3/7
- 在职业是程序员,体型是匀称有 3 共 1 个样本,则其概率为:1/3
- 则即是程序员又体型匀称的概率为:3/7 * 1/3 = 1/7
联合概率 + 条件概率:
在女神喜欢的条件下,职业是程序员、体重超重的概率? P(AB|C) = P(A|C) P(B|AC)
- 在女神喜欢的条件下,有 2、3、4、7 共 4 个样本
- 在这 4 个样本中,职业是程序员有 3、4 共 2 个样本,则其概率为:2/4=0.5
- 在在 2 个样本中,体型超重的有 4 共 1 个样本,则其概率为:1/2 = 0.5
- 则 P(程序员, 超重|喜欢) = 0.5 * 0.5 = 0.25
简言之:
条件概率:在去掉部分样本的情况下,计算某些样本的出现的概率,表示为:P(B|A)
联合概率:多个事件同时发生的概率是多少,表示为:P(AB) = P(B)*P(A|B)
【理解】贝叶斯公式
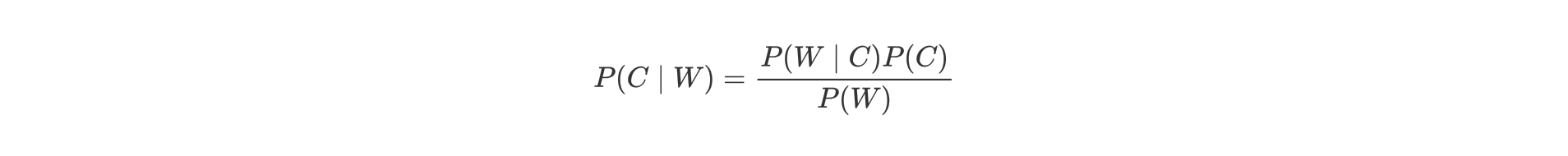
- P(C) 表示 C 出现的概率
- P(W|C) 表示 C 条件 W 出现的概率
- P(W) 表示 W 出现的概率

- P(C|W) = P(喜欢|程序员,超重)
- P(W|C) = P(程序员,超重|喜欢)
- P(C) = P(喜欢)
- P(W) = P(程序员,超重)
- 根据训练样本估计先验概率P(C):P(喜欢) = 4/7
- 根据条件概率P(W|C)调整先验概率:P(程序员,超重|喜欢) = 1/4
- 此时我们的后验概率P(C|W)为:P(程序员,超重|喜欢) * P(喜欢) = 4/7 * 1/4 = 1/7
- 那么该部分数据占所有既为程序员,又超重的人中的比例是多少呢?
- P(程序员,超重) = P(程序员) * P(超重|程序员) = 3/7 * 2/3 = 2/7
- P(喜欢|程序员, 超重) = 1/7 ➗ 2/7 = 0.5
【理解】朴素贝叶斯
我们发现,在前面的贝叶斯概率计算过程中,需要计算 P(程序员,超重|喜欢) 和 P(程序员, 超重) 等联合概率,为了简化联合概率的计算,朴素贝叶斯在贝叶斯基础上增加:特征条件独立假设,即:特征之间是互为独立的。
此时,联合概率的计算即可简化为:
- P(程序员,超重|喜欢) = P(程序员|喜欢) * P(超重|喜欢)
- P(程序员,超重) = P(程序员) * P(超重)
【知道】拉普拉斯平滑系数
由于训练样本的不足,导致概率计算时出现 0 的情况。为了解决这个问题,我们引入了拉普拉斯平滑系数。
我们只需要知道为了避免概率值为 0,我们在分子和分母分别加上一个数值,这就是拉普拉斯平滑系数的作用。
【案例】情感分析
学习目标:
1.知道朴素贝叶斯的API
2.能够应用朴素贝叶斯实现商品评论情感分析
【知道】api介绍
- sklearn.naive_bayes.MultinomialNB(alpha = 1.0)
- 朴素贝叶斯分类
- alpha:拉普拉斯平滑系数
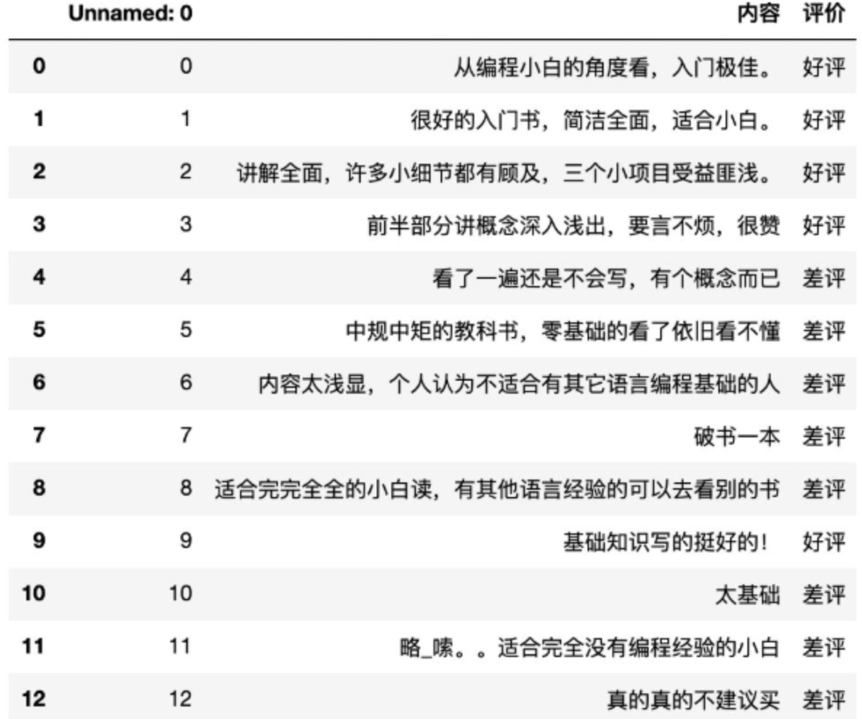
【实践】商品评论情感分析
已知商品评论数据,根据数据进行情感分类(好评、差评
步骤分析
- 1)获取数据
- 2)数据基本处理
- 2.1) 取出内容列,对数据进行分析
- 2.2) 判定评判标准
- 2.3) 选择停用词
- 2.4) 把内容处理,转化成标准格式
- 2.5) 统计词的个数
- 2.6)准备训练集和测试集
- 3)模型训练
- 4)模型评估
代码实现
1 | import pandas as pd |
- 1)获取数据
1 | # 加载数据 |
- 2)数据基本处理
1 | # 2.1) 取出内容列,对数据进行分析 |
- 3)模型训练
1 | # 构建贝叶斯算法分类器 |
- 4)模型评估
1 | mb.score(x_text, y_text) |
聚类
聚类算法简介
学习目标:
1.知道什么是聚类
2.了解聚类算法的应用场景
3.知道聚类算法的分类
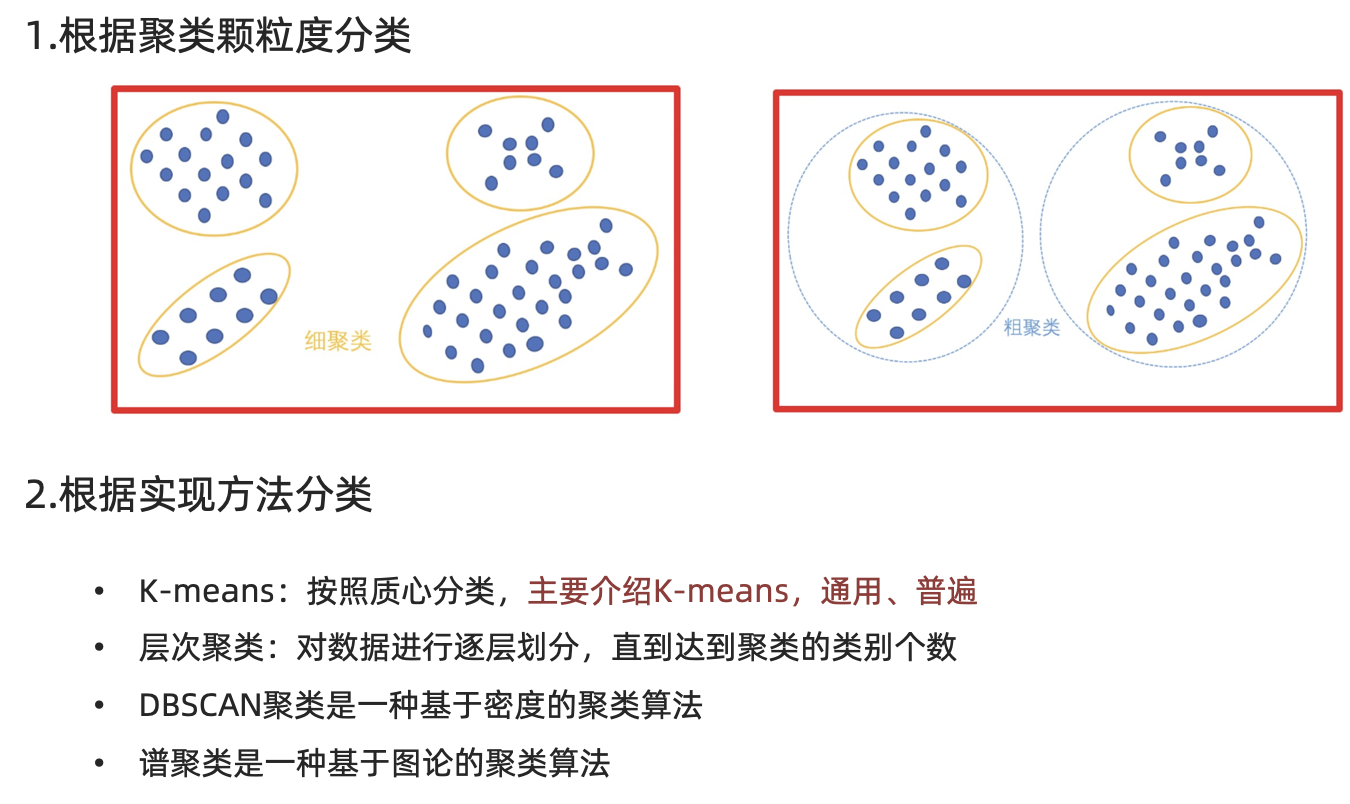
【知道】聚类算法介绍
一种典型的无监督学习算法,主要用于将相似的样本自动归到一个类别中。
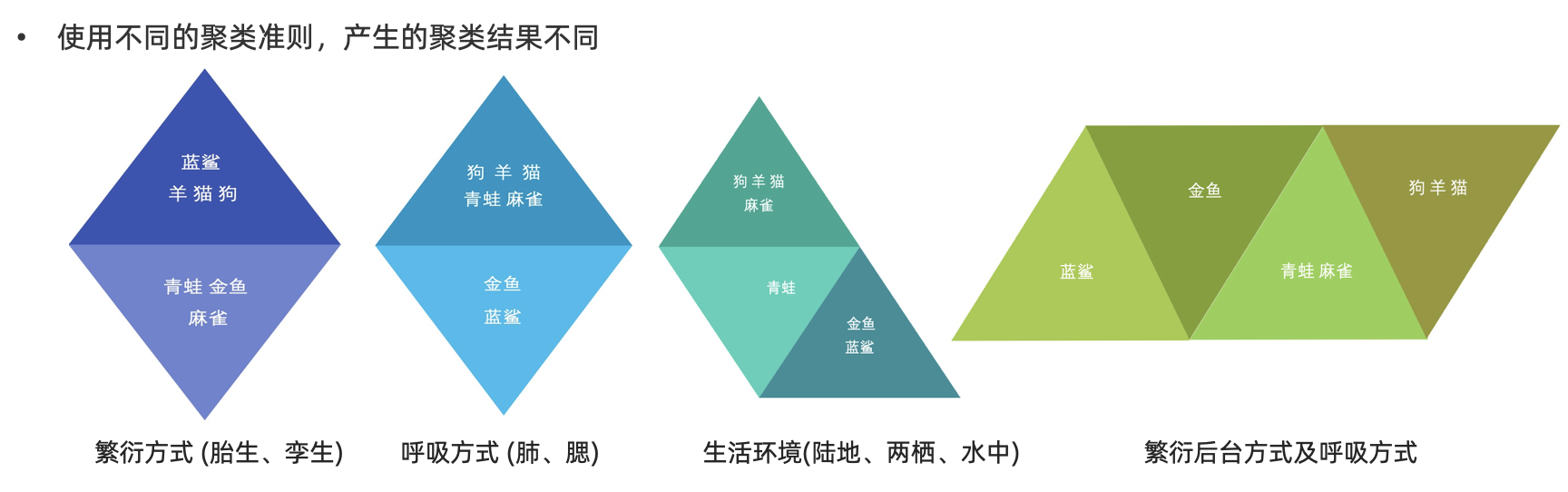
在聚类算法中根据样本之间的相似性,将样本划分到不同的类别中,对于不同的相似度计算方法,会得到不同的聚类结果,常用的相似度计算方法有欧式距离法。
【了解】聚类算法在现实中的应用
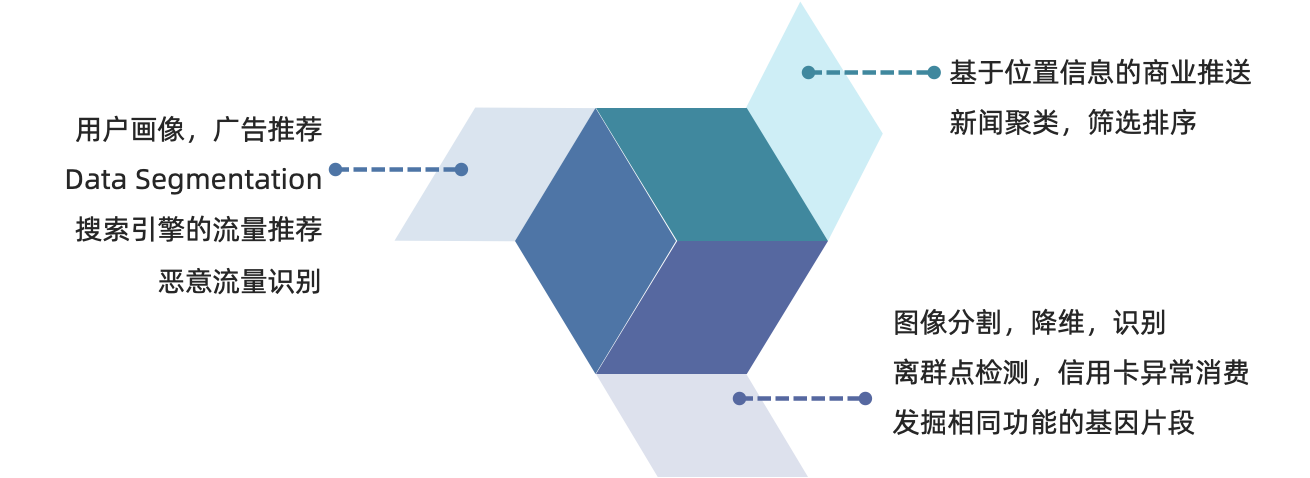
- 用户画像,广告推荐,Data Segmentation,搜索引擎的流量推荐,恶意流量识别
- 基于位置信息的商业推送,新闻聚类,筛选排序
- 图像分割,降维,识别;离群点检测;信用卡异常消费;发掘相同功能的基因片段
【知道】分类
聚类API的初步使用
学习目标:
1.了解Kmeans算法的API
2.动手实践Kmeans算法
【了解】api介绍
- sklearn.cluster.KMeans(n_clusters=8)
- 参数:
- n_clusters:开始的聚类中心数量
- 整型,缺省值=8,生成的聚类数,即产生的质心(centroids)数。
- n_clusters:开始的聚类中心数量
- 方法:
- estimator.fit(x)
- estimator.predict(x)
- estimator.fit_predict(x)
- 计算聚类中心并预测每个样本属于哪个类别,相当于先调用fit(x),然后再调用predict(x)
- 参数:
【实践】 案例
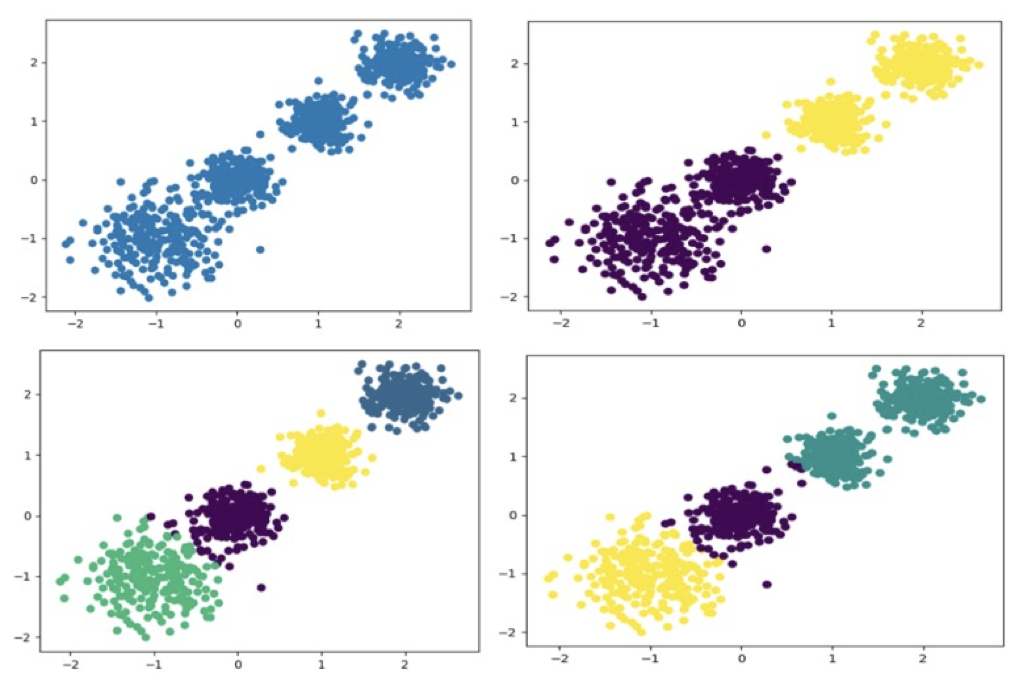
随机创建不同二维数据集作为训练集,并结合k-means算法将其聚类,你可以尝试分别聚类不同数量的簇,并观察聚类效果:
1.创建数据集
1 | import matplotlib.pyplot as plt |
2.使用k-means进行聚类,并使用CH方法评估
1 | y_pred = KMeans(n_clusters=2, random_state=9).fit_predict(X) |
Kmeans算法流程
学习目标
1、理解Kmeans算法的执行过程
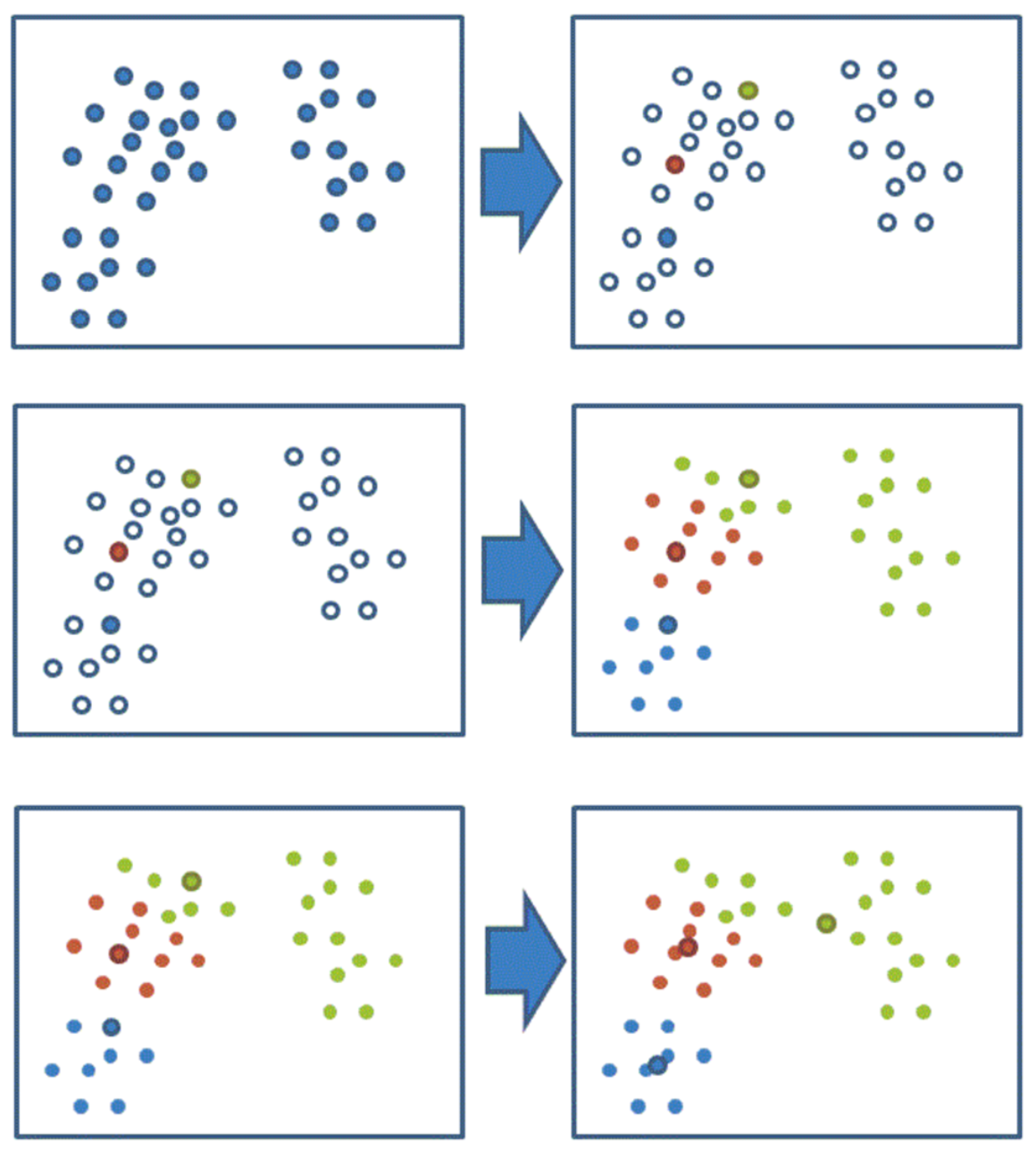
【掌握】k-means聚类流程
1、随机设置K个特征空间内的点作为初始的聚类中心
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
4、如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程
通过下图解释实现流程:
k-means聚类动态效果图:
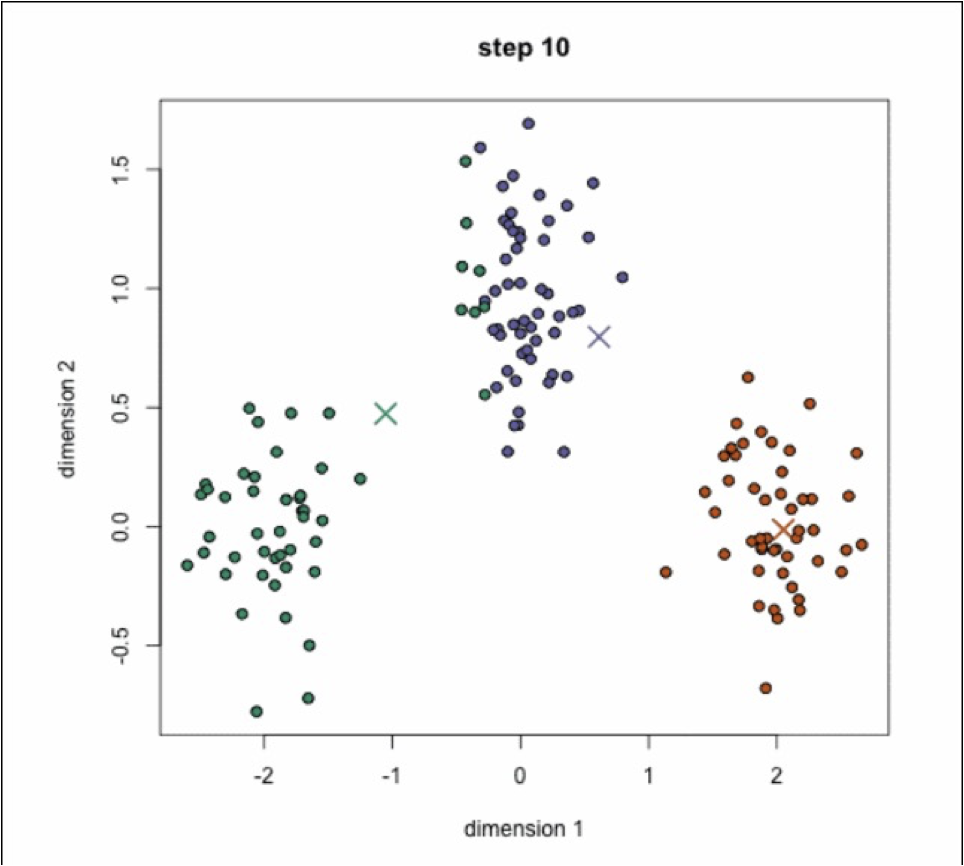
【练习】案例练习
- 案例:
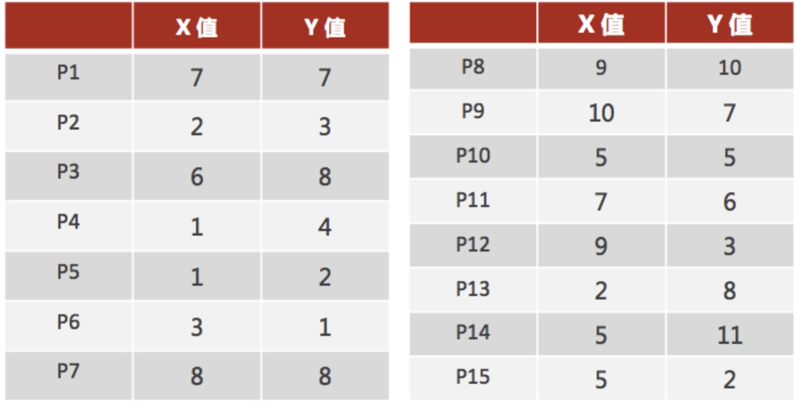
1、随机设置K个特征空间内的点作为初始的聚类中心(本案例中设置p1和p2)
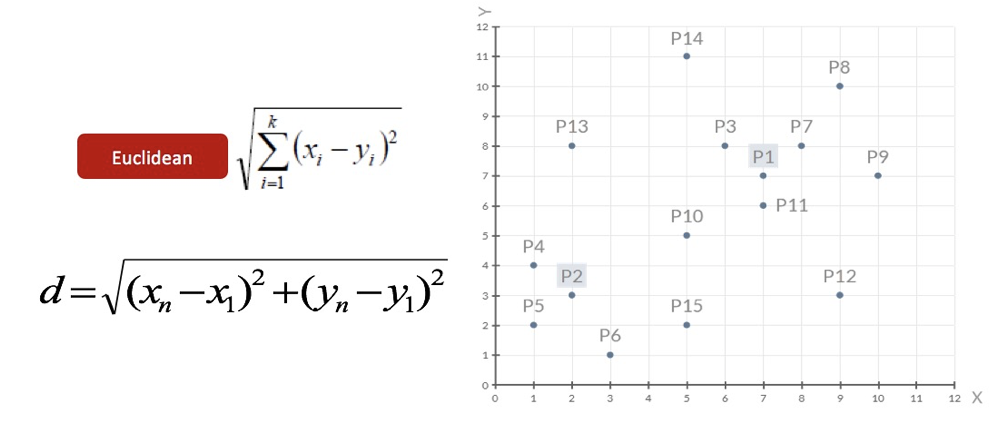
2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
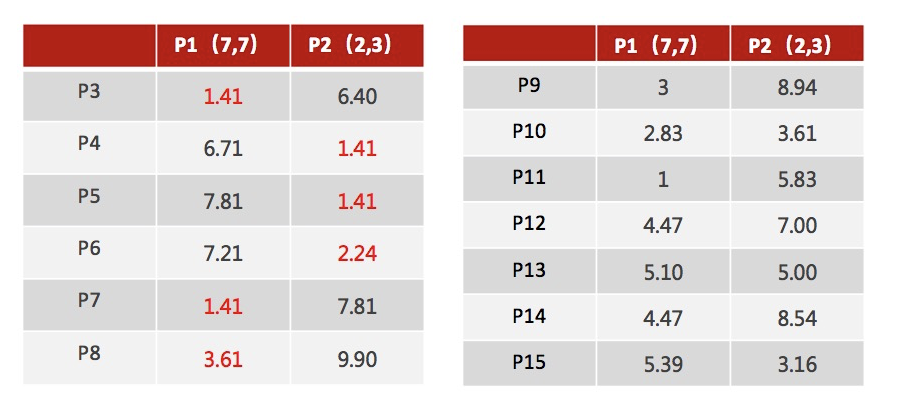
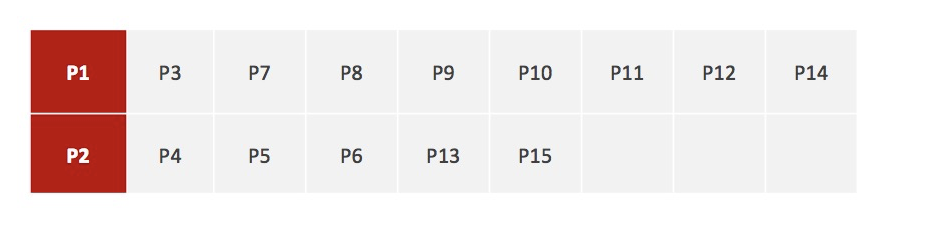
3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
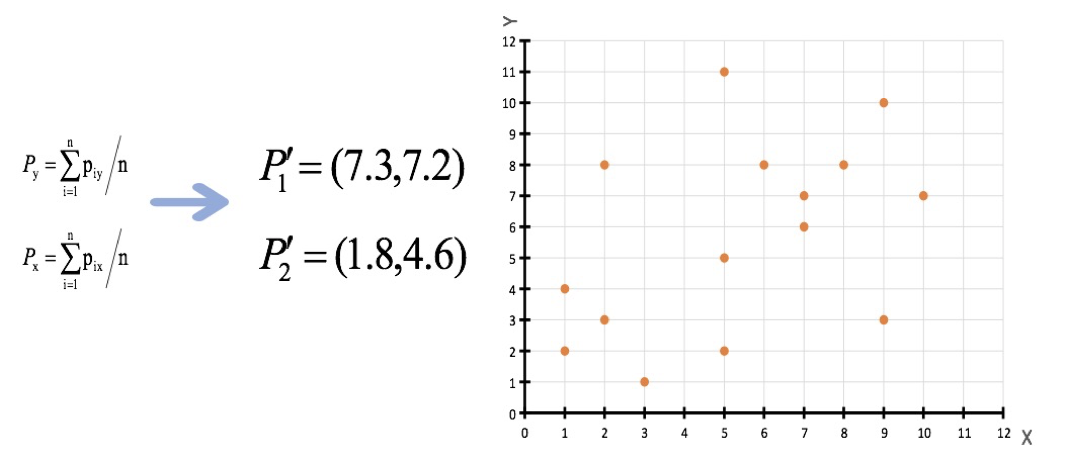
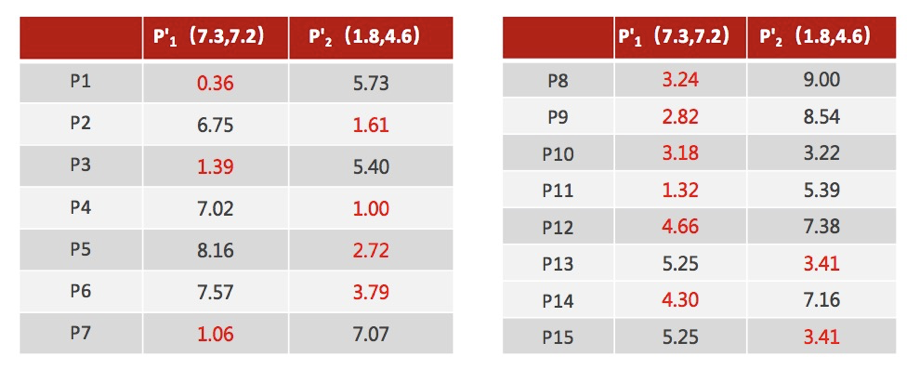
注意:这里P2′=(2.3,3.3),下同。
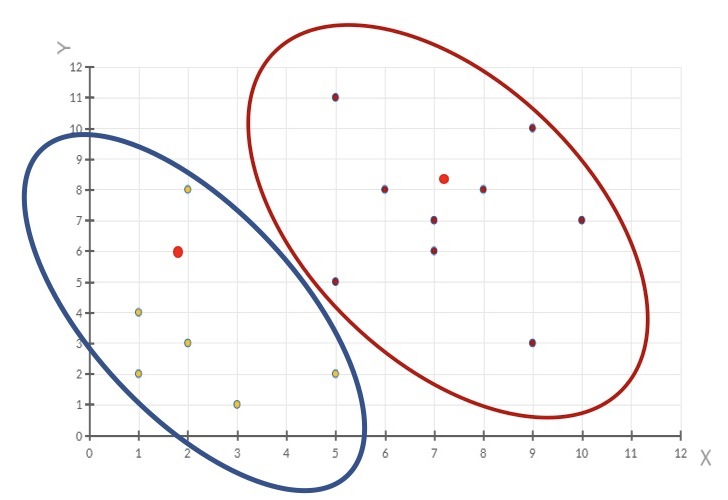
4、如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程【经过判断,需要重复上述步骤,开始新一轮迭代】

5、当每次迭代结果不变时,认为算法收敛,聚类完成,K-Means一定会停下,不可能陷入一直选质心的过程。
评价指标
学习目标:
- 了解 SSE 聚类评估指标
- 了解 SC 聚类评估指标
- 了解 CH 聚类评估指标
- 了解肘方法的作用
【了解】 SSE-误差平方和
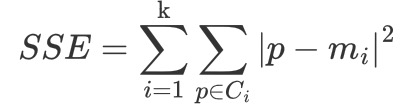
K 表示聚类中心的个数
Ci 表示簇
p 表示样本
mi 表示簇的质心
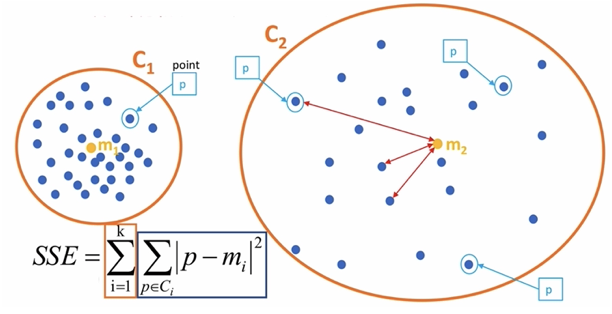
SSE 越小,表示数据点越接近它们的中心,聚类效果越好。
【了解】SC 系数
结合了聚类的凝聚度(Cohesion)和分离度(Separation),用于评估聚类的效果。
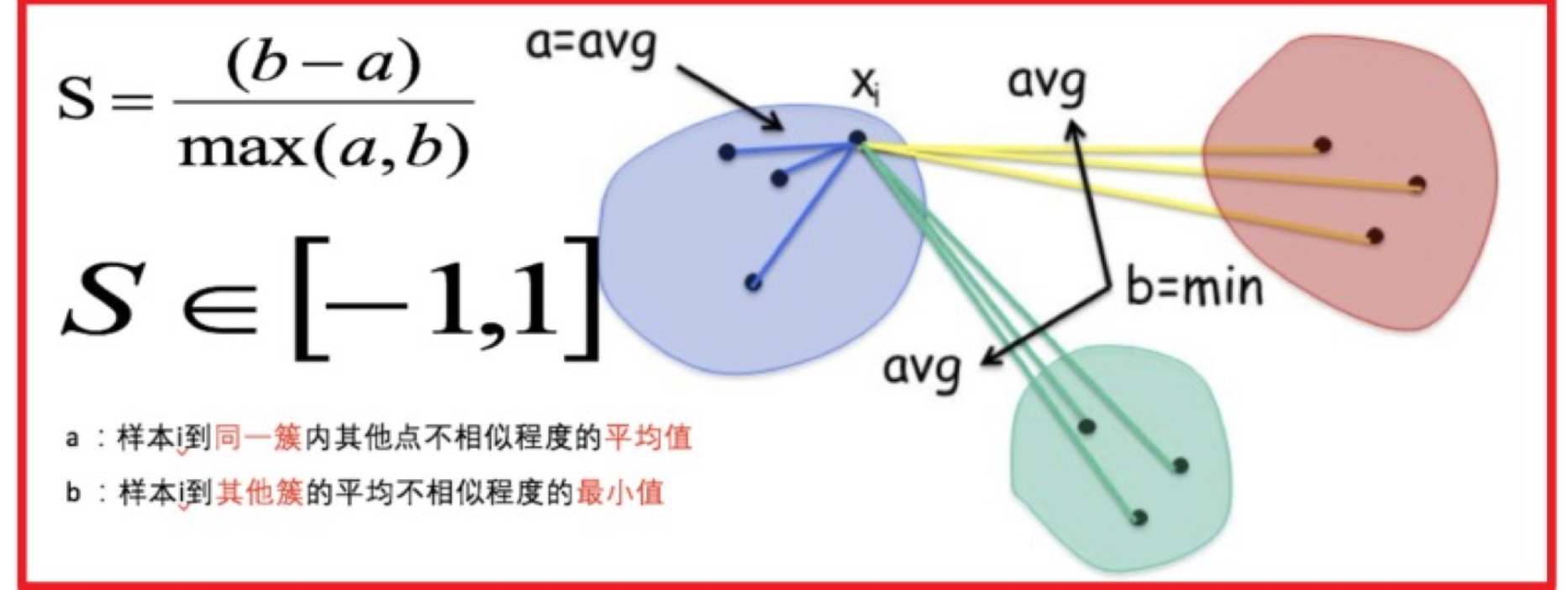
其计算过程如下:
- 计算每一个样本 i 到同簇内其他样本的平均距离 ai,该值越小,说明簇内的相似程度越大
- 计算每一个样本 i 到最近簇 j 内的所有样本的平均距离 bij,该值越大,说明该样本越不属于其他簇 j
- 计算所有样本的平均轮廓系数
- 轮廓系数的范围为:[-1, 1],值越大聚类效果越好
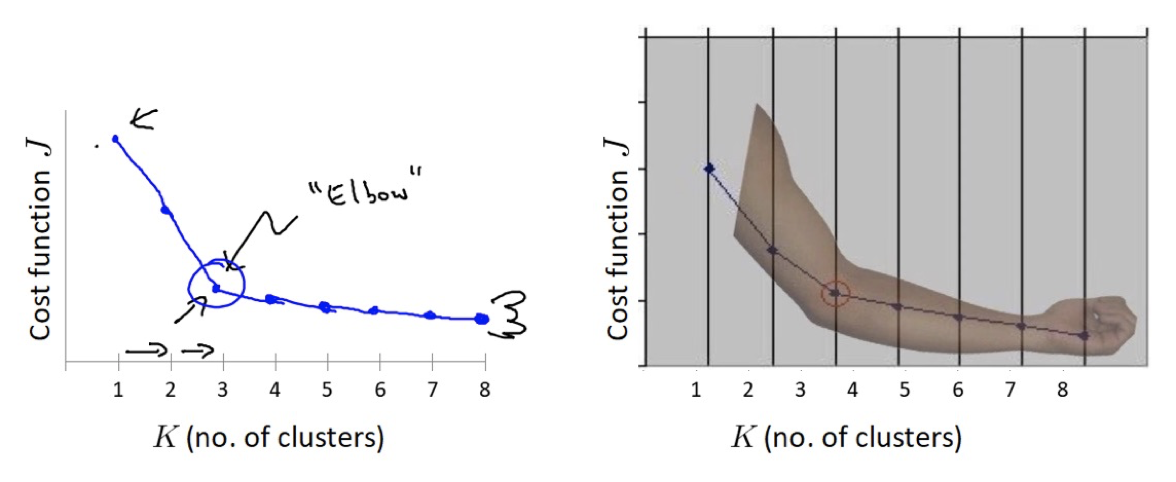
【了解】肘部法
肘部法可以用来确定 K 值.
对于n个点的数据集,迭代计算 k from 1 to n,每次聚类完成后计算 SSE
SSE 是会逐渐变小的,因为每个点都是它所在的簇中心本身。
SSE 变化过程中会出现一个拐点,下降率突然变缓时即认为是最佳 n_clusters 值。
在决定什么时候停止训练时,肘形判据同样有效,数据通常有更多的噪音,在增加分类无法带来更多回报时,我们停止增加类别。
【了解】CH 系数
CH 系数结合了聚类的凝聚度(Cohesion)和分离度(Separation)、质心的个数,希望用最少的簇进行聚类。
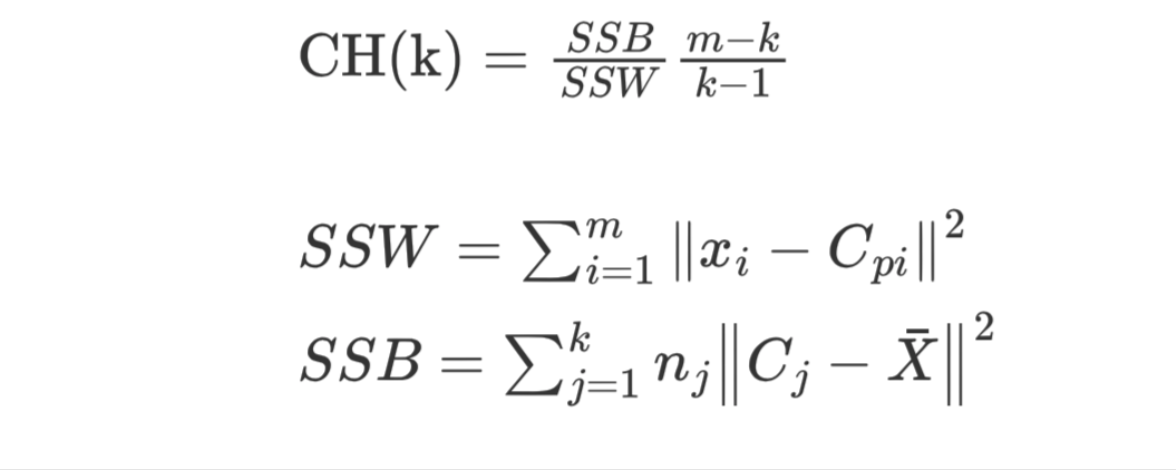
SSW 的含义:
- Cpi 表示质心
- xi 表示某个样本
- SSW 值是计算每个样本点到质心的距离,并累加起来
- SSW 表示表示簇内的内聚程度,越小越好
- m 表示样本数量
- k 表示质心个数
SSB 的含义:
- Cj 表示质心,X 表示质心与质心之间的中心点,nj 表示样本的个数
- SSB 表示簇与簇之间的分离度,SSB 越大越好
【实践】聚类评估的使用
1 | from sklearn.datasets import make_blobs |
【实践】案例
【了解】案例介绍
已知:客户性别、年龄、年收入、消费指数
需求:对客户进行分析,找到业务突破口,寻找黄金客户
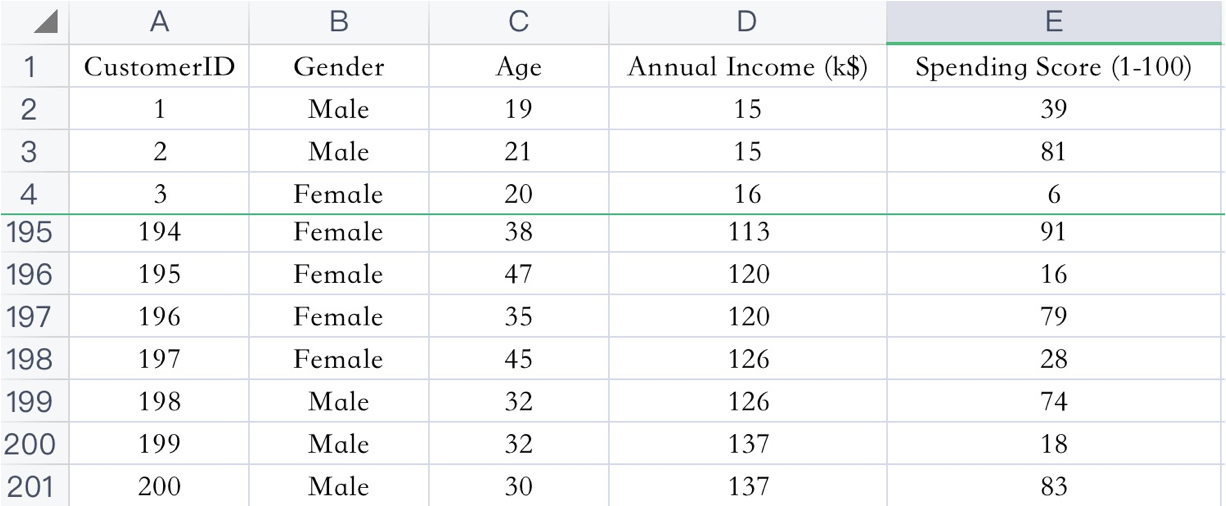
数据集共包含顾客的数据, 数据共有 4 个特征, 数据共有 200 条。接下来,使用聚类算法对具有相似特征的的顾客进行聚类,并可视化聚类结果。
【实践】案例实现
1 | import matplotlib.colors |